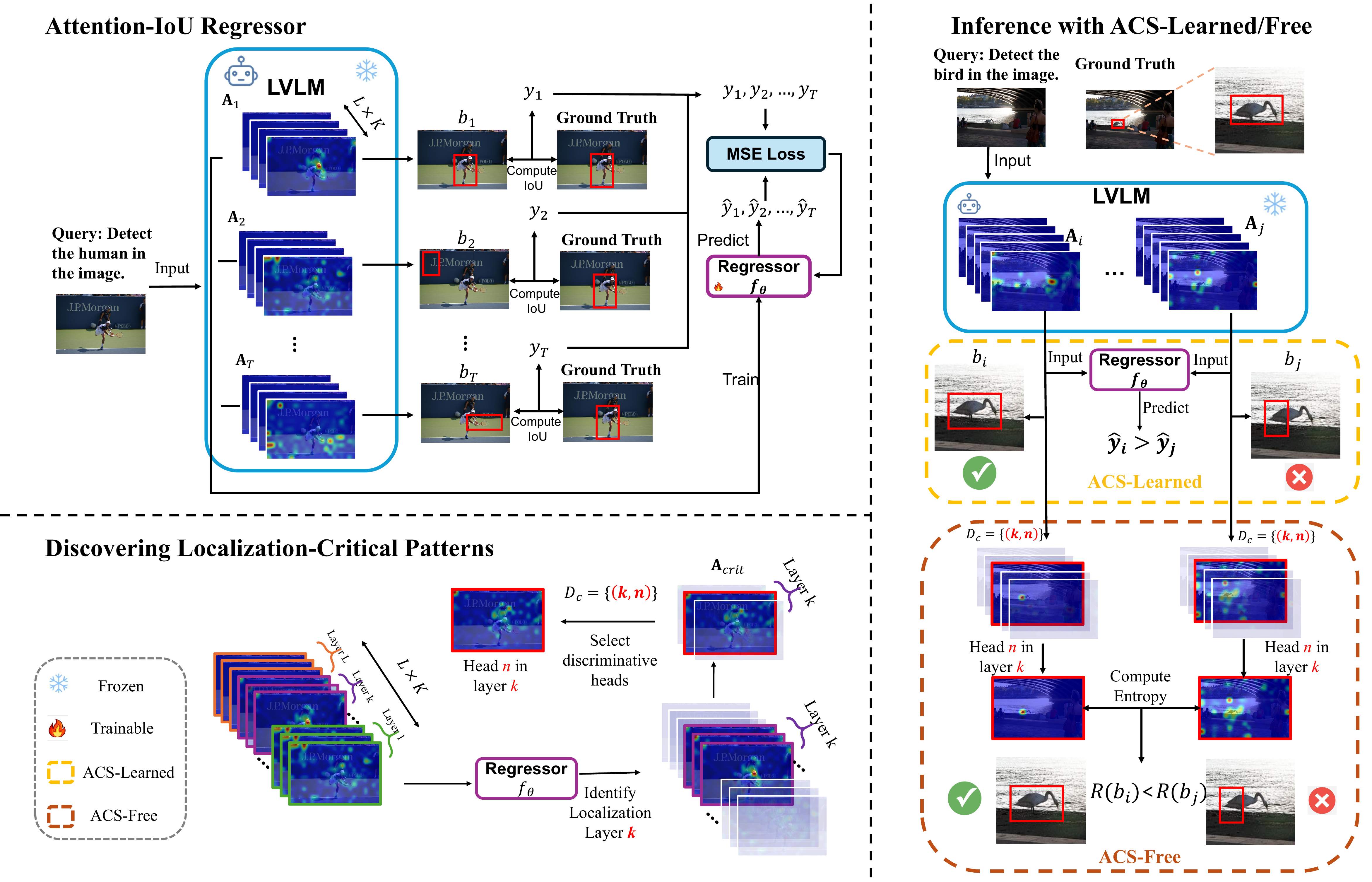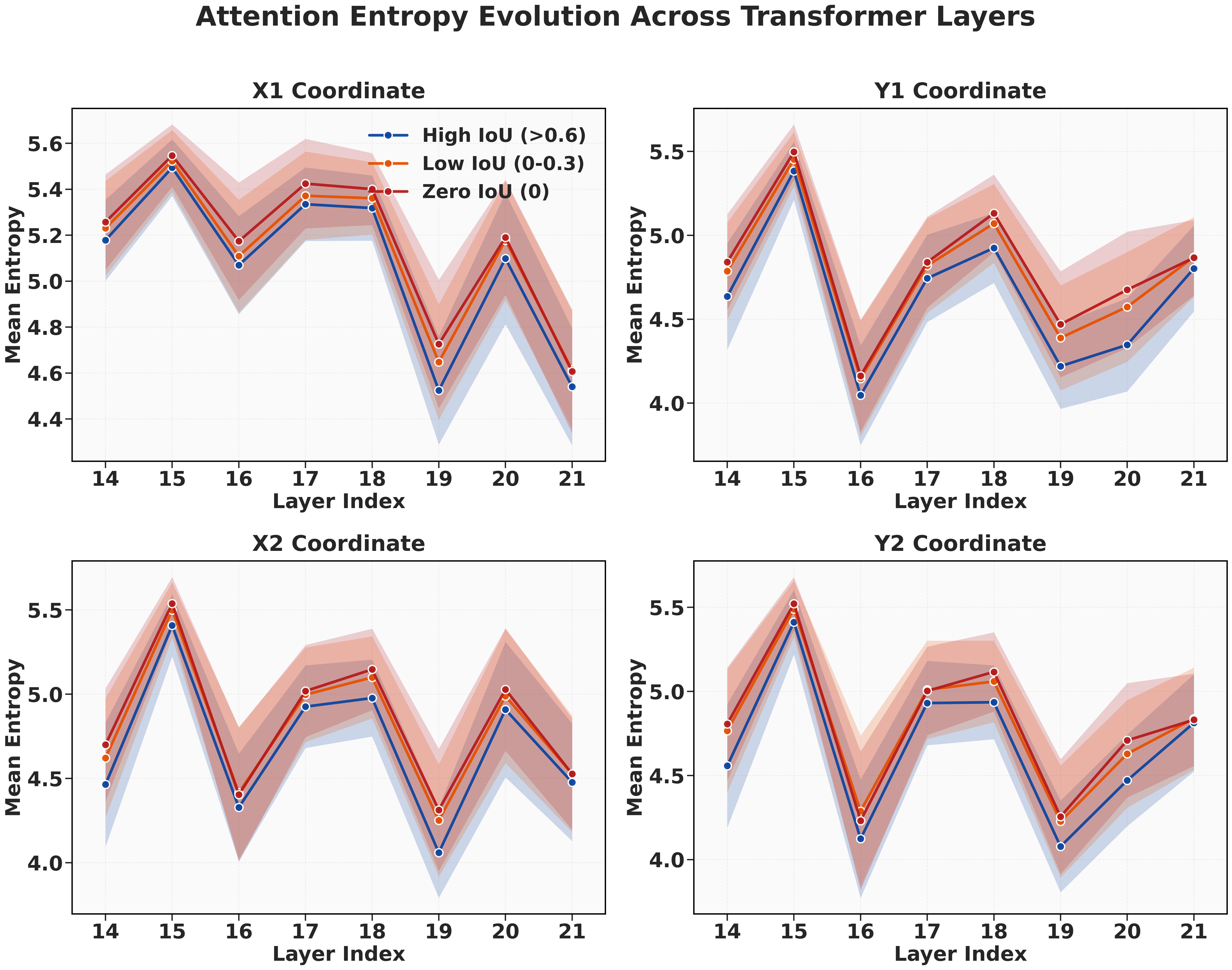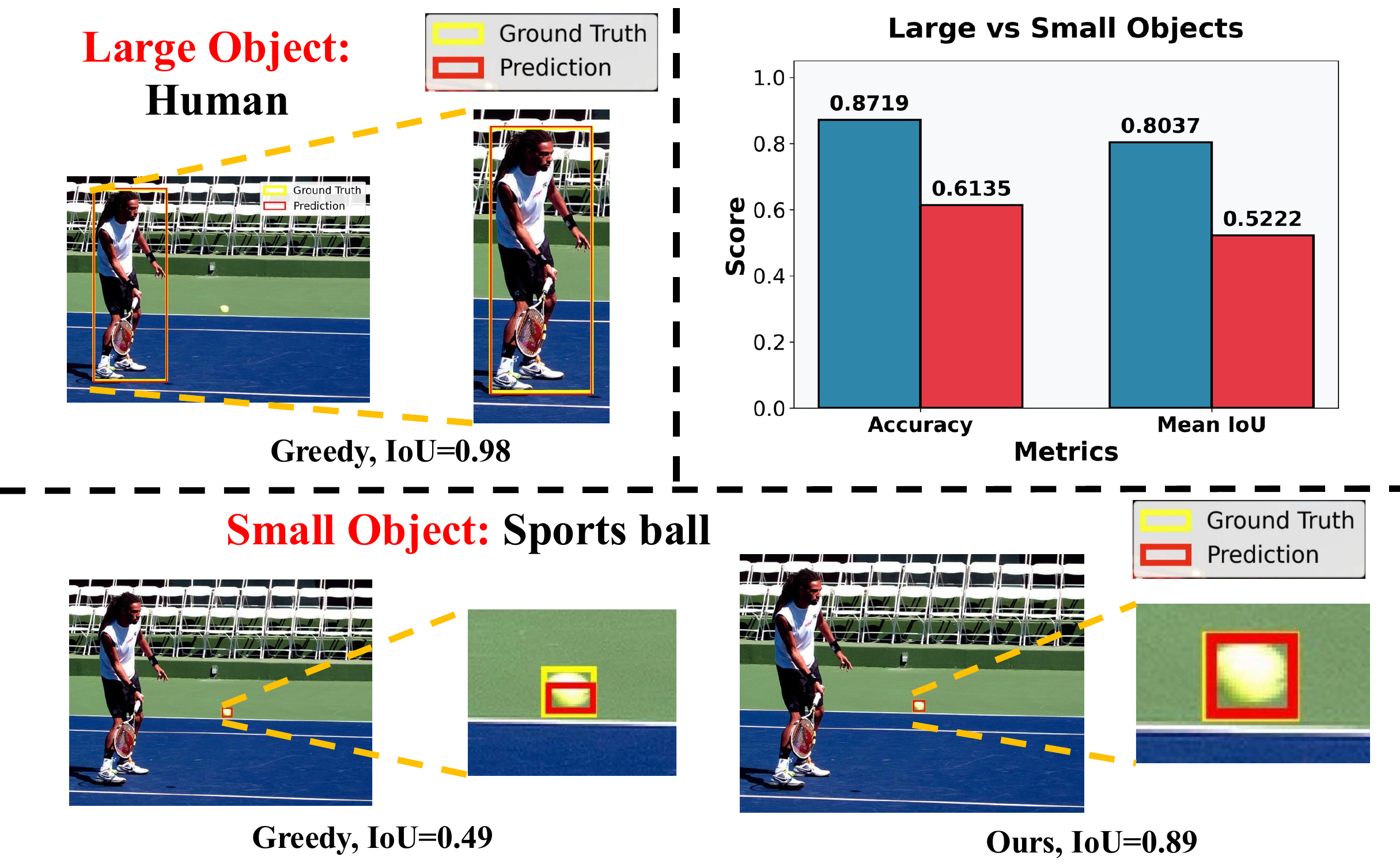
The problem
Small objects break LVLM localization
State-of-the-art LVLMs such as Qwen2.5-VL and InternVL-3.5 can output bounding boxes directly, no detection head required. Yet performance collapses on small objects — exactly the distant pedestrians, signs, and tools that matter most for safety-critical perception.
Prior fixes add fine-tuning, external detectors, or hand-tuned decoding — all of which cost compute or change the model. We ask whether the model's own internal signals are enough.